五筆字型輸入法은 中國語 漢字 字型을 基盤으로 한 中國語 入力方式이다. 첫 公開는 1986年이고, 한때 中國大陸에서는 漢字入力手段 그 自體로 認識되었으나 只今은 스마트해진 倂音入力에 밀리고 있다.
倉頡輸入法과 마찬가지로 漢字 讀音을 몰라도 字型만 알면 (大部分) 入力 코드를 推測할 수 있는 長點을 가진다. 이름이 "五筆"이지만 한 漢字에 配當된 코드는 3~4字이다. 모바일用 漢字 入力方式인 五筆劃과는 다른 方式이다.
劃數가 적은 簡體字에 알맞게 字根은 작게 設計되고, 打字할 때 中華人民共和國에서 整備한 標準 漢字 字型과 筆順에 따라 字根을 入力한다. 例: 判은 日本式(丷干刂)도 아니고, 韓國式(八一ナ刂)도 아니고, 꼭 中國式(䒑ナ刂, UDJH)으로 入力해야 한다.
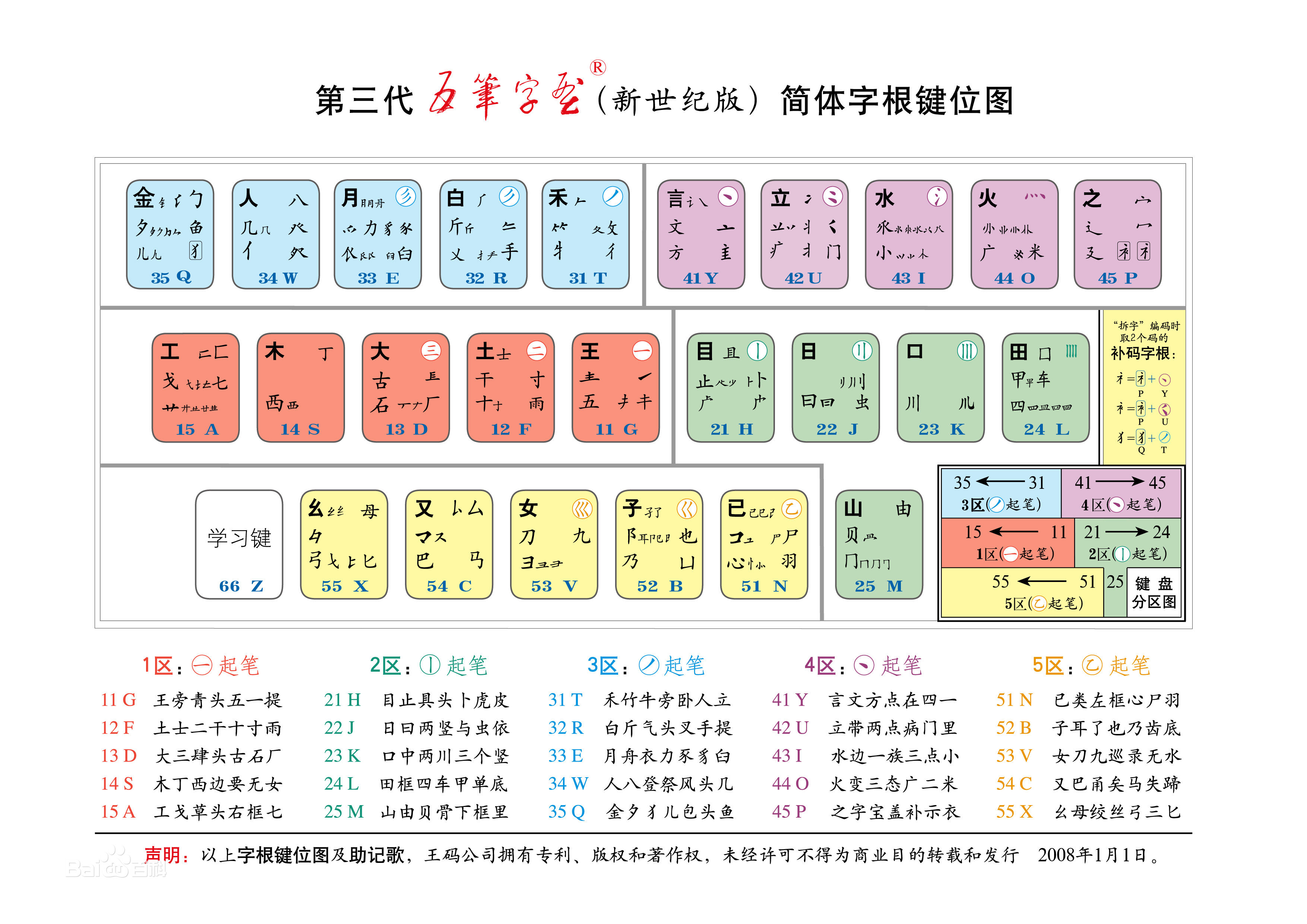
86版, 98版, 新世紀版이라는 出市年代로 命名된 3가지 버전이 있다. 字根 制定 原理는 差異가 거의 없으나, 一部 字根의 키 配當 變更과 98版부터의 繁體字 入力을 爲한 큰 字根의 追加 때문에 버전間 互換性이 없는 것으로 해도 無妨. 86版은 애초에 GB2312에 包含한 6700餘個 簡體字만 支援했는데, 後에 打字 規則 變更 없이 CJK統合漢字 2萬字 모두 支援하게 되었다. 卽, 日本과 韓國 漢字도 86版에서 入力할 수 있는 것.
가장 많이 쓰이는 버전은 86版이다. 特許期限이 滿了되었기 때문에, 五筆을 支援하는 많은 機器에서는 86版만 支援하고 其他 버전을 支援하지 않는다.
86版만 支援하는 機器/소프트웨어/OS
세 버전 모두 支援
한 劃을 分斷해서 字根으로 보는 倉頡과 다르게 五筆은 劃을 分斷하지 않는다. 例를 들면 果는 倉頡로 "田木(WD)"로 入力되고, 五筆로는 "日木(JS)I"로 入力된다.
複雜한 漢字는 첫 3個의 字根과 마지막 字根으로 入力된다. 예: 韓(FJNH) = 十(F) 早(J) ユ(N) 丨口匸(省略) 丨(H)
重複 코드를 避하기 爲해 識別 코드라는 機能이 있다. 그래도 어쩔 수 없이 코드가 똑같은 漢字가 몇 個 있다. 예: 赢羸嬴(YNKY), 微徽徵黴(TMGT), 去云支(FCU). 多幸히 이것도 單語入力으로 避할 수 있다.
簡體中文 單語 入力도 可能. 繁體字를 많이 入力하거나 한 글字씩 入力을 願하는 使用者에게는 이 機能을 끄는 것을 推薦하나, 中國語 簡體字로 된 文章을 入力할 때 큰 도움이 되기는 한다. 短點은 이 機能을 잘 利用하기 爲해서는 자주 使用하는 單語와 새롭게 나온 單語를 設定에 미리 登錄해야 便利하게 쓸 수 있는 點. (倂音은 클라우드 入力 機能이 發達하고 새 단어 업데이트도 頻繁하나 五筆은 아직도 그렇게 便利한 入力機가 없다.)
以下는 86版 爲主로 說明.
~
`
|
!
1
|
@
2
|
#
3
|
$
4
|
%
5
|
^
6
|
&
7
|
*
8
|
(
9
|
)
0
|
_
-
|
+
=
|
Backspace
|
| Tab
|
35
|
34
|
33
|
32
|
31
|
41
|
42
|
43
|
44
|
45
|
{
[
|
}
]
|
|
\
|
| Caps Lock
|
15
|
14
|
13
|
12
|
11
|
21
|
22
|
23
|
24
|
:
;
|
"
'
|
Enter
|
| Shift
|
채움[4]
|
55
|
54
|
53
|
52
|
51
|
25
|
<
,
|
>
.
|
?
/
|
Shift
|
| Ctrl
|
Win
|
Alt
|
Space
|
Alt
|
Win
|
Menu
|
Ctrl
|
- 키보드를 5大區域×5키로 分配하고 番號를 配置 [5]
- 字根은 첫 劃따라 5大區域으로 分配 (一1X, 丨2X, 丿3X, 丶4X, 乙乚5X).
- 한 劃만으로 된 字根은 X1키에 配置 ("한 一"자는 11, "丿"는 31)
- 첫 劃을 反復하는 걸로 構成된 字根은, 反復하는 回數따라 配置 (二는 12, 彡는 33, 巛는 53, 灬는 44)
- 字根의 두번째 劃도 (一1, 丨2, 丿3, 丶4, 乙乚5)이렇게 配置 (大犬石는 13, 匚匸는 15, 冂는 25, 勹夕儿는 35, 言广方는 41, 之冖는 45, 已尸는 51)
- 그리고 數없이 많은 例外... [6]
字根을 외우기 쉽게 詩처럼 생긴 구결이 있다.
86版 字根 口訣
|
1 |
2 |
3 |
4 |
5
|
| 1區域(一) |
G 王旁青头[7]戋五一 |
F 土士二干十寸雨 |
D 大犬三羊[8]古石厂 |
S 木丁西 |
A 工戈草头[9]右框[10]七
|
| 2區域(丨) |
H 目具[11]上止卜虎皮[12] |
J 日早两竖[13]与虫依[14] |
K 口与川,字根稀[15] |
L 田甲方框[16]四车力[17] |
M 山由贝,下框[18]几
|
| 3區域(丿) |
T 禾竹一撇[19]双人立[20],反文条头[21]共三一[22] |
R 白手[23]看头[24]三二斤[25] |
E 月彡[26]乃用[27]家衣底[28] |
W 人和八[29],三四里[30] |
Q 金勺缺点[31]无尾鱼[32],犬旁[33]留儿一点夕[34],氏无七[35]
|
| 4區域(丶) |
Y 言文方广在四一[36],高头[37]一捺谁人去[38] |
U 立辛两点[39]六门疒 |
I 水旁[40]兴头[41]小倒立[42] |
O 火业头[43],四点[44]米 |
P 之字军盖[45]道建底[46],摘礻衤[47]
|
| 5區域(乚) |
N 已半巳满不出己[48],左框[49]折尸[50]心[51]和羽[52] |
B 子耳[53]了[54]也[55]框向上[56] |
V 女刀九臼山朝西[57] |
C 又[58]巴马,丢矢矣[59] |
X 慈母无心[60]弓和匕,幼无力[61]
|
86版 字根表 (이미지 形式)
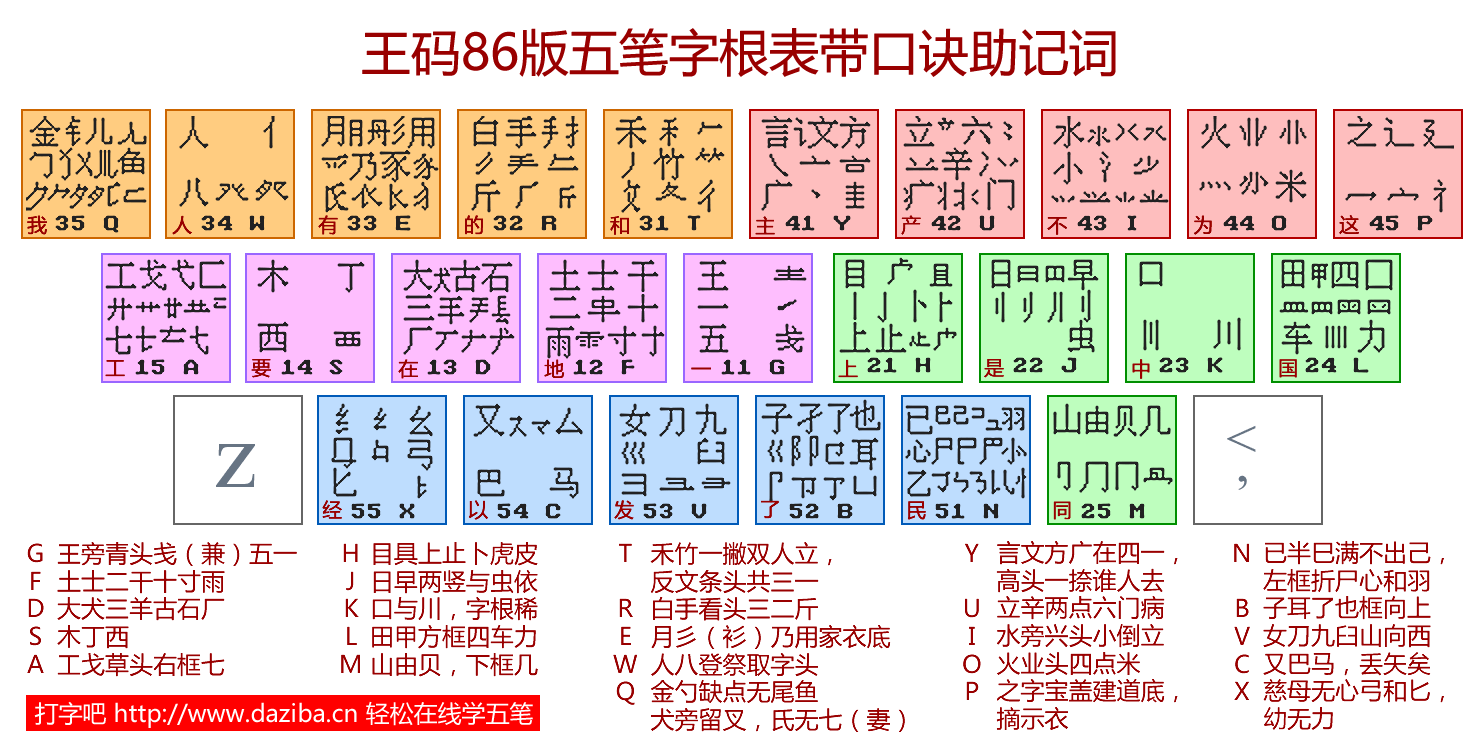
以下 例示 코드는 86版을 基準으로 한다. 其他 버전에서는 같은 글字여도 코드가 다를 수 있다.
키를 대표하는 字根. 口訣에서 가장 먼저 나오는 字根. 입력할 때 키를 4番 누르면 됨.
例: 王(GGGG), 金(QQQQ), 大(DDDD)
(例外: X 키는 纟)
字根 自體를 入力할 때, 다음과 같은 順序로 入力. 劃은 (一G, 丨H, 丿T, 丶Y, 乚N) 5個의 키만으로 나타냄.
- 字根 키
- 字根字 筆順 첫 劃
- 字根字 筆順 두番째 劃
- 字根字 筆順 마지막 劃 (없으면 省略)
- 例
- 犬(DGTY) = 字根키(D) 一(G) 丿(T) 丶(Y)
- 力(LTN) = 字根키(L) 丿(T) 𠃌(N)
- 辛(UYGH) = 字根키(U) 丶(Y) 一(G) 丨(H)
字根字가 1劃인 경우, 字根키 2番과 LL로 入力.
- 例
- 一(GGLL)
- 乙(NNLL)
入力機 코드表에 存在하지 않는 字根은 入力할 수 없음.
字根이 아닌 字를 入力할 때, 中國 漢字의 筆順 따라 漢字를 字根으로 分解하고 하나씩 入力.
- 例
- 例(WGQJ) = 亻(W) 一(G) 夕(Q) 刂(J)
- 书(NNHY) = 𠃌𠃌丨丶
- 约(XQY) = 纟勹丶
- 达(DP) = 大辶[62]
字根이 너무 많으면 中間의 字根을 省略한다.
- 첫번째 字根
- 두번째 字根
- 세번째 字根
- 마지막 字根
例: 赢(YNKY) = 亠乚口(月贝几)丶
五筆의 哲學에서, 字根間의 關係를 4種類로 分類:
- 单: 字根 하나만으로 漢字가 됨. 例: 口,竹
- 散: 明白하게 이어지지 않는 여러 部分으로 된 漢字. 例: 散, 好
- 连: 筆劃들이 서로 接觸한다. 例: 天(一과 大의 接觸), 午(𠂉와 十의 接觸), 矢
- 交: 筆劃이 다른 劃을 꿰뚫는다. 例: 夫(人이 二를 貫通), 牛, 失
破字法:
- 取大优先: 큰 字根을 選好함. 例: 平(一丷一丨 ❌)(一䒑丨 GUH⭕)[63].
- 兼顾直观: 直觀性도 重視. 直觀性을 爲해 筆順도 無視할 수 있음. 例: 來(木人人 SWWI), 来(一米 GOI). 國처럼 外廓이 字根이 된 境遇는 筆順上 外廓을 마지막으로 닫아야 되는데 五筆은 筆順을 無視하고 先外廓 後內容으로 處理.
- 能散不连,能连不交: 散으로 判斷할 수 있으면 連으로 處理하지 않고, 連이 보이는 字는 交로 處理하지 않는다. 이는 午(TFJ)와 牛(RHK), 矢(TDU)와 失(RWI) 등의 區分法.
漢字의 構造와 마지막 劃에 따라 識別코드로 入力코드를 채운다.
字型 識別 코드
| 構造 |
左右 |
上下 |
其他
|
| 一 |
11G |
12F |
13D
|
| 丨 |
21H |
22J |
23K
|
| 丿 |
31T |
32R |
33E
|
| 丶 |
41Y |
42U |
43I
|
| 乚 |
51N |
52B |
53V
|
例: "吗"字를 칠 때는 字根에 따라 KC를 친다. 근데 "吧"와 "邑", "叹"의 字根 코드도 KC다.
"吗"자의 마지막 劃은 一이고, 構造는 左右이기 때문에, 識別코드인 G를 KC뒤에 붙인다.
吗(KCG), 吧(KCN), 邑(KCB), 叹(KCY) 이렇게 區別할 수 있다.
但, 두 字根으로 組立된 字여도 그 中의 하나가 1획이면 上下/左右 構造가 아니고 一體構造로 認識됨.
例: 午(TFJ) = 𠂉十 + 上下構造(J)
千(TFK) = 丿十 + 一體構造(K)
2字 單語: "无限(FQBV)" = 无(FQV) + 限(BVE).
3字 單語: "国庆节(LYAB)" = 国(LGY) + 庆(YDI) + 节(ABJ).
4字 單語: "大韩民国(DFNL)" = 大(DDDD) + 韩(FJFH) + 民(NAV) + 国(LGY)
4字 以上 單語: "温故而知新(IDDU)" 温(IJLG) + 故(DTY) + 而(DMJJ) + 知(省略) + 新(USRH)
많이 쓰인 漢字를 한 키로 入力할 수 있게 만든 機能. 總 25字.
Q~P: 我人有的和 主产不为这
A~L: 工要在地一 上是中国
X~M: 经以发了民 同
該當 키를 한 番만 누르면 簡略코드 漢字가 候補 1位에 올리고, 스페이스 키로 入力한다.
注意할 點은, 이 코드는 單語入力에 쓸 수 없다. 例: 为什么(YWTC)는 OWTC로는 입력할 수 없다.
2級, 3級 簡略코드도 存在하지만, 漢字組立規則대로도 入力할 수 있으니 따로 외우지 않아도 됨.
1980年代 中國社會에는 컴퓨터가 잘 處理하지 못하는 漢字가 中國의 現代化를 막고 있다는 漢字破棄論이 나왔는데, 五筆字型輸入法 等 漢字 電算化의 成果가 續出하고 나서는 이런 소리를 듣기 힘들어졌다.
創製 時期는 1980年代라 많은 어려움을 겪어 왔다고 創製者 王永民氏가 밝혔다. 왜냐하면 6700餘個 漢字를 하나씩 머리써서 字根과 코드를 指定하는 것 自體도 무거운 任務이고, 破字法이나 字根이 하나라도 變動하면 一部 漢字의 코드를 다시 指定해야 하기 때문이다.
字根 指定이 手作業이니 만큼, 破字法을 따르지 않는 "事實上 틀린" 코드도 있고, 이를 修正한 코드表를 使用했는지는 入力機마다 다른 狀況도 있다...[64]
以下 例示는 따로 註釋 없이 86版 코드.
| 漢字 |
三星키보드·윈도우 |
Gboard |
公式홈피[65]
|
| 兆[66] |
IQV |
QII, IQV[67] |
QII
|
| 逃 |
IQPI |
QIPI |
QIPI
|
| 桃 |
SIQY |
SQIY |
SQIY
|
| 垂 |
TGAF[68] |
TFAG[69] |
TFAG
|
| 锤 |
QTGF |
QTFG, QTGF |
QTFG
|
| 乗[70] |
TGAS[71] |
TGAI[72] |
결과 없음
|
98版은 一部 漢字의 破字法을 變更했는데 新世紀版은 이를 一部 撤回. 가장 有名한 例示는 戍.
赢羸嬴 系列의 重複코드 問題를 解決하는 試圖로 98版에는 (亡口)를 쌓은 字根을 만들었고 41Y키에 配當했는데, 新世紀版에서는 撤回하고 重複된 채로 維持.
五筆字型 홈페이지에서는 버전間 差異를 이렇게 說明했다. "86版은 가장 많이 쓰이고, 新世紀版은 字根 코드 配當이 가장 合理的이고, 98版은 過渡期 버전이다." [83] 이런 意味에서 애플이나 中國産IME로 五筆을 쓰려고 하는 사람에게는 新世紀版을 推薦하고, 그 다음에는 86版을 推薦한다.
打字速度의 向上 等을 爲해, 五筆의 基本 破字法을 遵守하면서 字根을 追加하거나 破字法을 細微한 調整하고, 새로운 五筆을 만드는 것에 힘쓰는 매니아層도 있다. 그들이 만든 새로운 코드表는 WubiLex, Rime 等의 소프트를 통해 OS에 實裝하고 使用할 수 있다.
가장 代表적인 民間 버전은 091五筆과 092五筆.
- ↑ 標準規則을 遵守하지 않는 點이 있어서, 初步者에게는 非推薦
- ↑ 五筆을 發明한 王永民氏가 設立한 會社가 開發한 윈도우만 支援하는 入力機, 有料로 提供
- ↑ 中國 스마트폰 製造社도 大部分 Sogou 入力機를 基本 搭載, 中國版 갤럭시도 마찬가지
- ↑ 모르는 字根을 Z로 代替
- ↑ 쉽게 說明하기 爲해서만 키를 番號로 부르고, 五筆 코드를 나타낼 때는 알파벳으로
- ↑ 위 順序만으로는 23는 川자만으로 쓰고, 14는 아예 비워야 되고, 口田日目처럼 많이 쓰는 字根은 다 25로 가야 되는 非合理的인 分配로 되버린다. 그래서 위의 第2條를 지키는 狀態로 區域 안의 字根들은 어느程度 不規則적으로 配置되었다.
98版, 新世紀版과 86版과의 差異는 이 點에만 볼 수 있다. 例를 들면 广자가 86版에는 41키지만 98版에는 44키로 가버렸다.
- ↑ 青자의 머리
- ↑ 羊에서 丷를 빠진다
- ↑ 艹
- ↑ 匚
- ↑ 具에서 八를 빠진다
- ↑ 虎皮의 껍데기만
- ↑ 刂
- ↑ 虫과 함께라는 뜻
- ↑ 字根이 적다는 뜻
- ↑ 國·圍자의 外廓
- ↑ 力자가 3區域이나 5區域에 가야되는 意見도 있음
- ↑ 冂, 그리고 骨자의 윗部分
- ↑ 丿
- ↑ 彳
- ↑ 夂,条자의 머리
- ↑ 이들이 함께 31키를 채웠다는 뜻
- ↑ 𠂉아래에 一 字根도 포함
- ↑ 看자의 머리
- ↑ 丘자의 아래 一를 뺀 字根도 包含
- ↑ 爫도 包含
- ↑ 舟자 머리의 點을 뺀 字根도 包含
- ↑ 家와 衣자의 아랫부분
- ↑ 八자처럼 생긴 점도 포함
- ↑ 34키에 들어있다는 뜻. 口訣에서 未包含인 癶, 그리고 祭자의 머리도 34키에 있다.
- ↑ 勹
- ↑ 魚자의 윗부분만
- ↑ 犭
- ↑ 夕에서 點을 뺀 도 包含
- ↑ 氏자가 七를 뺀 字根
- ↑ 41키에 들어있다는 뜻, 讠도 포함
- ↑ 亠와 高자의 윗부분(亠口 합침)
- ↑ 隹에서 亻를 뺀 부분
- ↑ 點 두個, 凍자의 部首 等
- ↑ 氵
- ↑ 兴자의 윗部分, 一자 包含
- ↑ 小자를 꺼꾸로 된 字根
- ↑ 業자의 머리, 그리고 그 꺼꾸로
- ↑ 點 네個
- ↑ 冖宀
- ↑ 辶廴
- ↑ 이 두 部首의 오른쪽 點을 딴(摘) 상태. 두 部首를 나타내려면 PY나 PU로
- ↑ 已己巳 다 包含
- ↑ コユ
- ↑ 民자가 七를 뺀 字根도 包含
- ↑ 忄⺗도 포함
- ↑ 习자는 未包含. 그리고 똑바르지 않는 한 획으로 된 字根들은 다 51키 所屬. 韓國 國字에 쓰는 ㄱ과 ㅇ도 51키(但 支援하는 入力機가 많지 않음).
- ↑ 卩阝도 包含
- ↑ 矛予의 아랫部分
- ↑ 㔾도 包含
- ↑ 凵
- ↑ 西쪽으로 向한 山, 卽 彐. 참고로 虐자의 아랫부분은 AG로 나타냄.
餘談으로 倉頡도 女자를 V키에 配置
- ↑ マス도 包含
- ↑ 矣자의 矢를 잃었다는 뜻. 卽 厶
- ↑ 母자의 外廓
- ↑ 幺, 그리고 互자의 中間部分
- ↑ 辶部의 漢字는 辶를 마지막으로 쓴다. 識別코드는 I
- ↑ 後者는 3劃의 "큰" 字根을 包含해서 選好함.
參考로 한 글자에는 하나의 코드만 許容.
- ↑ 86版 코드表는 GitHub등에서 쉽게 求할 수 있지만, 그게 修正前인지 修正後인지는...
- ↑ http://www.wangma.net.cn/search.aspx?sm=7
- ↑ 字根은 水자外廓에 儿. 差異點은 打字 順序.
- ↑ 後에 追加
- ↑ 丿一艹士
- ↑ 丿十廿一
- ↑ 日本字型. 中韓에는 乘자.
- ↑ 丿一艹木. 근데 이거는 取大优先 原則대로 "禾廿"로 코드 指定하는 건 아냐?
- ↑ 丿一廿小
- ↑ 厂𠃌乚(丿)丶
- ↑ 厂乚丶丿. 修正後는 DNTY, 點을 마지막 劃으로. 三星·윈도우에는 修正前만 入力可能, Gboard에는 兩쪽 모두 可能. 以下同文.
- ↑ 厂一乚(丶)丿. 修正後는 DGNY.
- ↑ 厂丶乚(丶)丿. 修正後는 DYNY.
- ↑ V는 識別코드
- ↑ 98版에는 戊자가 字根이 되었다. GTY는 筆順.
- ↑ D는 識別코드
- ↑ 現代字型에는 이 4字는 비슷하게 생기지만, 戍자의 古典字型을 살펴보면 사람(人,W)이 武器(戈,A)를 잡고 守衛하는 모습에서 나온 漢字이고, 이를 따라 이런 코드를...
- ↑ 厂㐅丶+識別코드. "戊"字根을 撤回. 55X키에는 㐅字根을 추가, 다만 이거는 (乚丿)이고 35Q키에 있는 㐅(丿丶)와는 다른다. 成戌戍자 코드의 X도 모두 이 字根.
- ↑ 甚히 乖離한 破字法를 撤回.
- ↑ http://www.wangma.net.cn/pro.aspx?sm=2#:~:text=%E4%BF%9D%E5%AD%98%E8%80%8C%E4%B8%8D%E8%83%BD%E6%B3%84%E6%BC%8F%E3%80%82-,%E4%BA%94%E7%AC%94%E5%AD%97%E5%9E%8B2016,-%EF%BC%88%E4%BA%A7%E5%93%81%E4%BB%A3%E5%8F%B7%EF%BC%9AWM01

